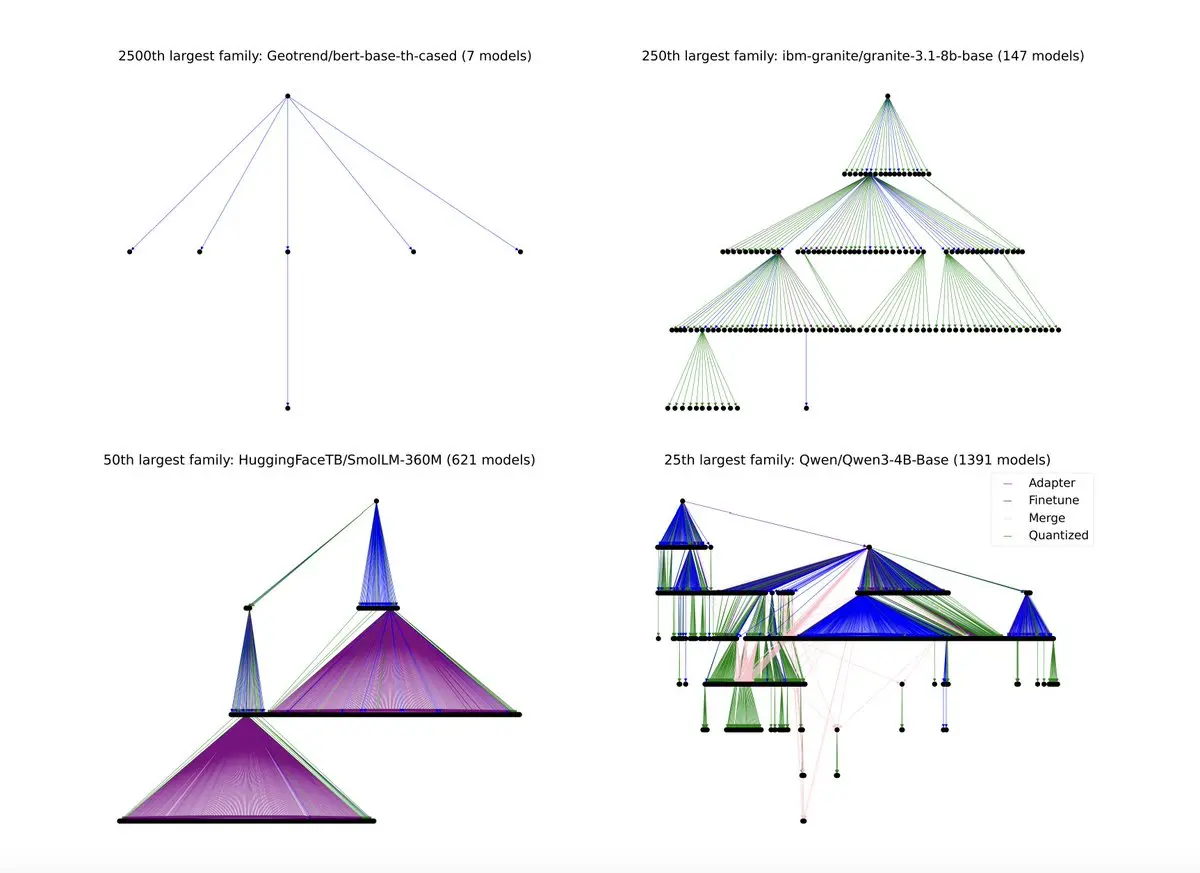
TokenTreasury_
Acabamos de lanzar 3 millones de muestras de un conjunto de datos de entrenamiento de modelo de lenguaje visual de alta calidad para casos de uso como:
📄 reconocimiento óptico de caracteres
🧠 detección de objetos
📊 comprensión de documentos
📄 reconocimiento óptico de caracteres
🧠 detección de objetos
📊 comprensión de documentos
VSN-2.75%